(a) Code des threads :

(b) Entrelacement invalide :

(c) Entrelacement correct :

Figure 1 : Entrelacements d'exécutions
Résumé : Cet article a pour but de démystifier la structure et le fonctionnement d'un noyau de systčme d'exploitation de type Unix, en présentant les éléments essentiels du coeur de Linux.
Les synchronisations les plus courantes sont les mutex (exclusion mutuelle), les sémaphores (protection de ressources constituées d'une quantité connue d'unités, comme des files de messages), les conditions (un thread se met en sommeil en attendant que la condition soit validée, ou signalée par un autre thread), ou encore les files de messages (analogie avec un pipe Unix).(a) Code des threads :
(b) Entrelacement invalide :
(c) Entrelacement correct :
Figure 1 : Entrelacements d'exécutions
Ce fonctionnement permet de simplifier le multitâche. D'une part, le chargement est simplifié : les adresses virtuelles de l'application peuvent ętre fixées indépendamment des adresses physiques, et donc des autres tâches déjŕ présentes. D'autre part il suffit que chaque application ait une configuration d'espace d'adressage en propre pour garantir le cloisonnement des espaces d'adressage, ou la protection mémoire des applications. Ce mécanisme n'interdit cependant pas ŕ plusieurs espaces d'adressage de se recouvrir en partie en mémoire physique : il y a alors partage possible de zones de mémoire physique.
Toutefois, le nombre de niveaux du mécanisme de pagination est dépendant de l'architecture. Par exemple, sur les processeurs x86, la pagination n'est que sur 2 niveaux : répertoire de pages puis tables de pages. Dans ce cas, les répertoires de pages "du milieu" ont une taille de une entrée. Toute la gestion de la mémoire virtuelle de Linux fonctionne comme si la pagination était ŕ 3 niveaux, et la partie dépendante de l'architecture (voir section 2.6) s'occupe de simuler cette pagination ŕ 3 niveaux avec le processeur disponible.
$ cat /proc/self/maps # address perms offset dev inode pathname 08048000-0804b000 r-xp 00000000 08:02 52439 /bin/cat 0804b000-0804c000 rw-p 00003000 08:02 52439 /bin/cat 0804c000-0804d000 rwxp 00000000 00:00 0 40000000-40011000 r-xp 00000000 08:02 16236 /lib/ld-2.3.1.so 40011000-40012000 rw-p 00011000 08:02 16236 /lib/ld-2.3.1.so 40026000-4012e000 r-xp 00000000 08:02 16241 /lib/libc-2.3.1.so 4012e000-40134000 rw-p 00107000 08:02 16241 /lib/libc-2.3.1.so 40134000-40137000 rw-p 00000000 00:00 0 bfffe000-c0000000 rwxp fffff000 00:00 0La premičre région est le code du programme exécuté, son adresse de début est indiquée dans l'exécutable, et est en général située ŕ l'adresse virtuelle 0x08048000 sur x86 (info ld). Cette région est en lecture et exécution seulement. La deuxičme région contient les données du programme exécuté, et est en lecture écriture. La région qui suit est le tas.
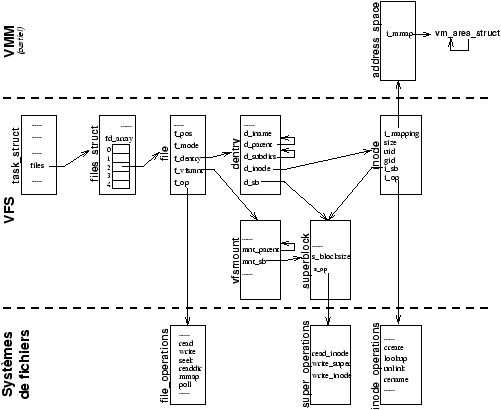
Pour une application utilisateur, un fichier ouvert correspond ŕ un entier. Pour tous les appels systčme de manipulation d'un fichier, le noyau utilise cet entier comme un index dans le tableau fd_array de la structure noyau include/linux/sched.h:files_struct propre ŕ chaque processus (champ files de include/linux/sched.h:task_struct). L'entrée correspondante fait référence ŕ un objet de type include/linux/fs.h:struct file.
| Thomas Petazzoni et David Decotigny Projet Kos (http://kos.enix.org) Thomas.Petazzoni@enix.org et d2@enix.org |
Ce document a été traduit de LATEX par HEVEA.